When I was looking at building the module that could attach additonal disks to servers in azure I know I needed to support the ability to add and potentially remove data disks without the risk of losing data. The two methods Terraform provides for dynamically creating a number of resources are Count and For_Each, and I thought I had read that resources created with the Count method would be completely destroyed and re-created if the list you are supplying to make the objects is modified.
I wrote this post because wanted to test how the two methods actually perform side by side and get an idea of how Terraform handles it when you modify the input variables for each method.
I’m going to quickly cover how my modules are set up, then I’m going to create some VMs using the managed disk module I have. On each VM I’m going to create three disks, attach them and add unique data, then I’ll remove the second disk to see what happens.
I’ll briefly touch on how to write count vs for_each meta-arguments, though Terraform’s documentation is so good that I don’t think it’s worth covering this in detail.
Note: I use the terms ‘method’ and ‘meta-argument’ interchangably when referring to count and for_each.
Terraform labels ‘count’ and ‘for_each’ as meta-arguments in their documentation. I usually just refer to them as methods, though I will sometimes describe them as meta-arguments because that’s how Terraforms documentation labels them.
Setting up the tests #
To test the individual meta-arguments I’m going to use the for_each module I wrote about in this post and just modify it for the count function as well.
For_each:
module "data_disk" {
source = "../terraform-azurerm-dzab-datadisk"
for_each = local.data_disks
resource_group = var.resourceGroup-name
region = var.resourceGroup-location
vm_id = azurerm_windows_virtual_machine.servervm.id
disk_name = format("${var.vm-name}-DSK-%02d", each.key)
disk_size = each.value
lun = lookup(local.luns, format("${var.vm-name}-DSK-%02d", each.key))
}
Count:
module "data_disk" {
source = "../terraform-azurerm-dzab-datadisk"
count = length(local.data_disks)
resource_group = var.resourceGroup-name
region = var.resourceGroup-location
vm_id = azurerm_windows_virtual_machine.servervm.id
disk_name = format("${var.vm-name}-DSK-%02d", count.index + 1)
disk_size = local.data_disks[count.index]
lun = lookup(local.luns, format("${var.vm-name}-DSK-%02d", count.index + 1))
}
The only real difference here to point out is that Count iterates based on a numerical value, which is usually just the length() of a list variable. So you reference each iterated value using count.index to represent the index of the object you are on.
For_each uses a map as the input instead, so you reference each iteration using each.key to represent the key of each attribute of the map, or each.value for the associated value.
Testing each on a VM #
Like I mentioned earlier, using each method I was going to perform the following steps:
- Create a VM with 3 additional disks using the modules above
- Once the VM was created, create a unique file on each disk to represent data on that disk
- Remove the second disk from the list/map I use to create them and update the VM
This is to see what happens when the input for the meta-arguments are changed for the resources they create. Based on my previous assumptions, the data would be retained correctly on the disks created by for_each, but I expected all the data to be removed when modifying the input for the module using count.
My results were not quite what I expected.
For_each #
Here’s the module I used to create my initial for_each configuration, I pass in a map with the disk number as the key and the size of the disk as the value:
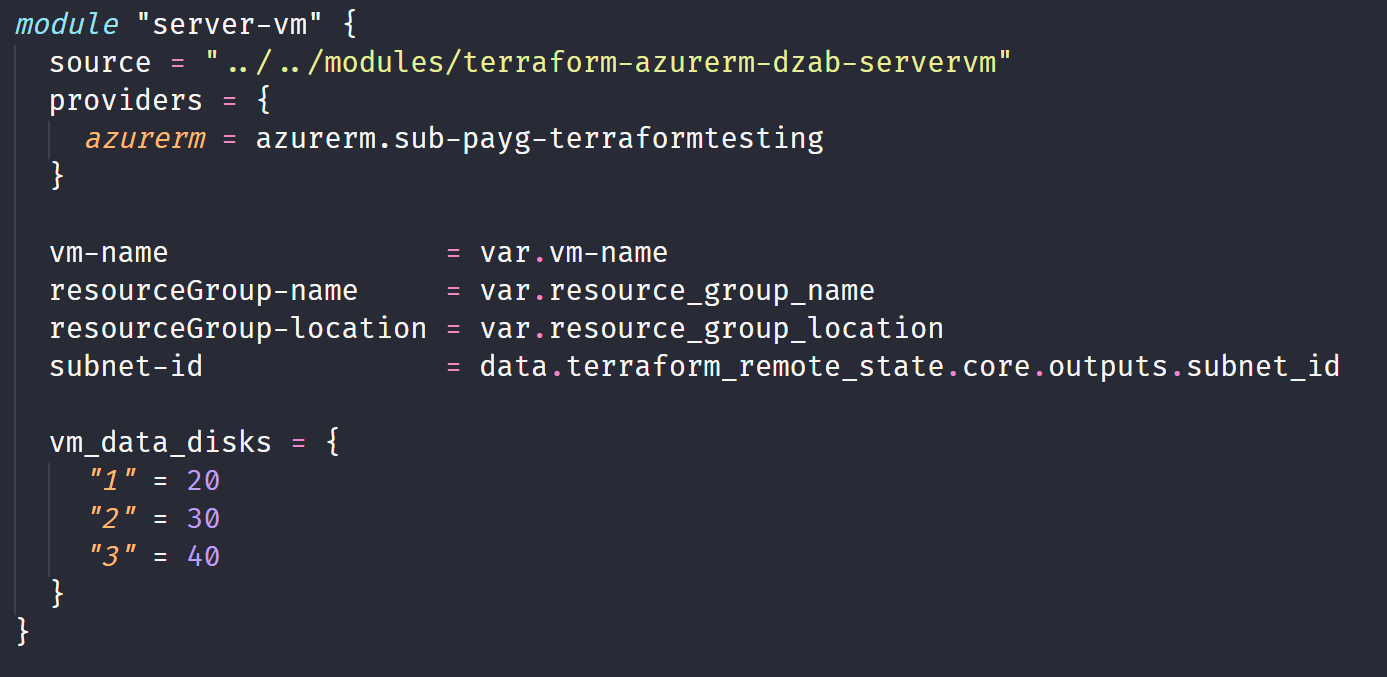
And then once I created the VM and initialized the disks, I created a text file on each name named with the Volume letter and the disk size:
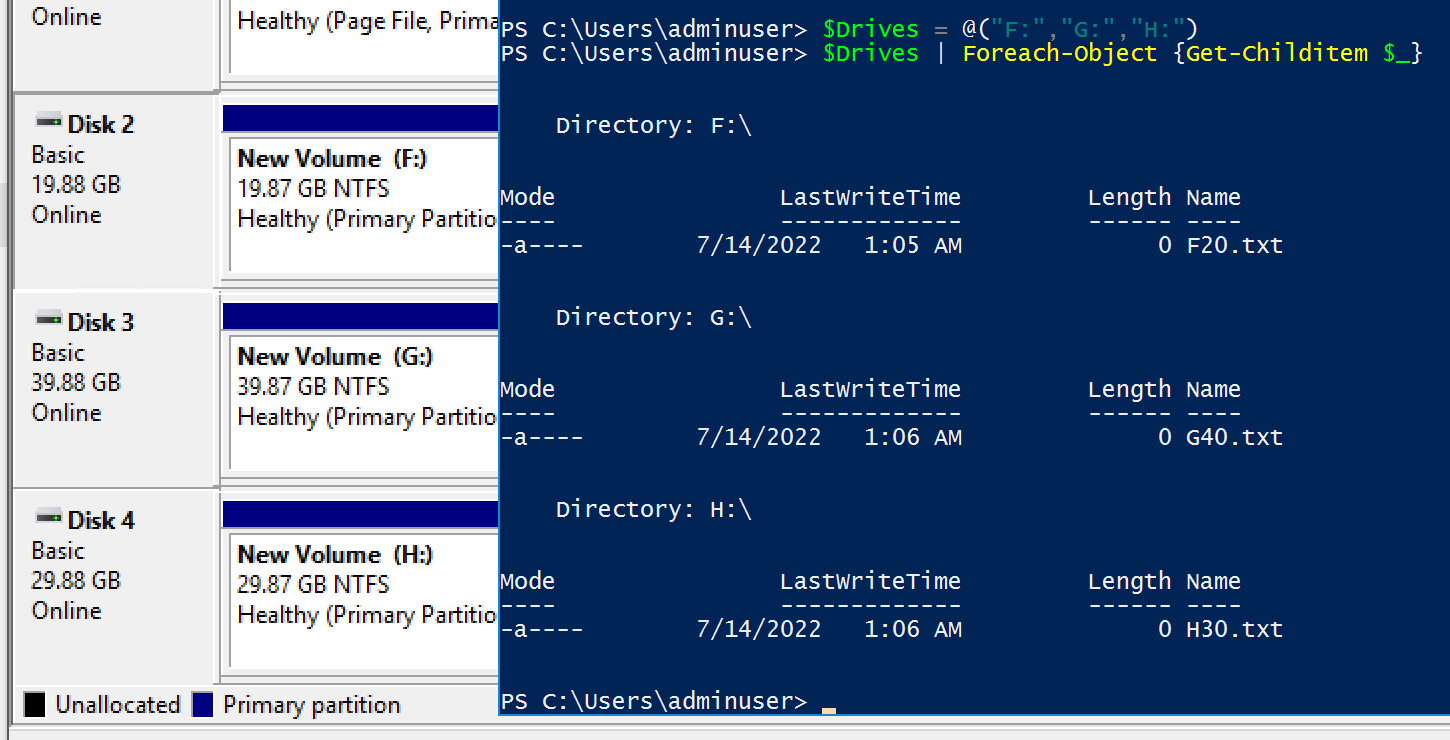
Now I had my baseline configured so to test changes to the module, I modified my vm_data_disks input variable to remove the second disk in the object:
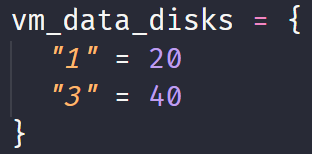
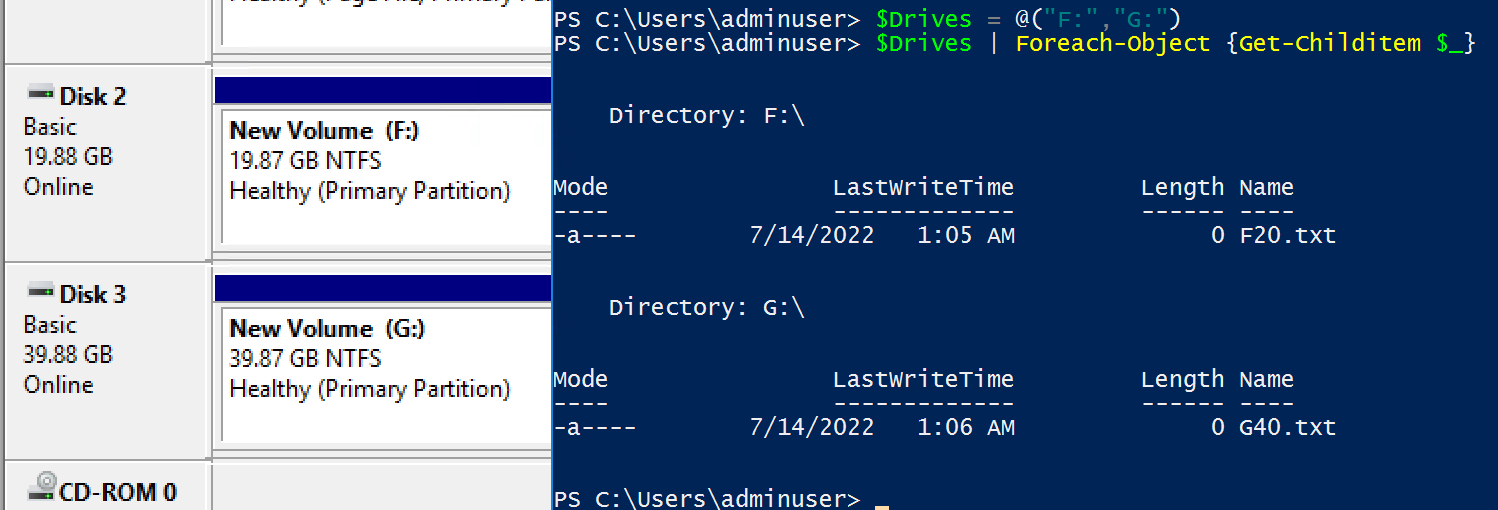
The results were what I expected. The second disk was removed, the text file I had created on the first and second disk was retained correctly and the volume numbers and disk sizes for the first and third disks were unchanged:
Count #
After copying my server-vm module, I updated the config to pass a list of the sizes I wanted each disk and then performed the same text file set up:
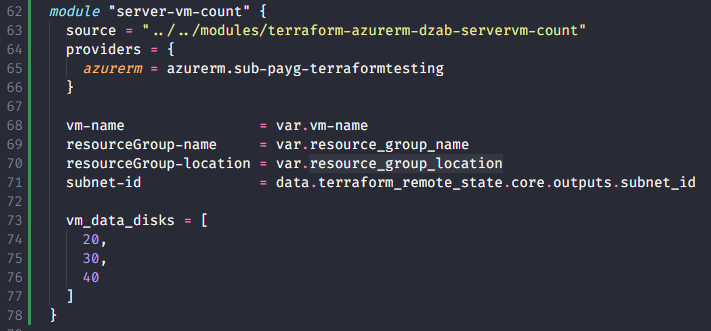
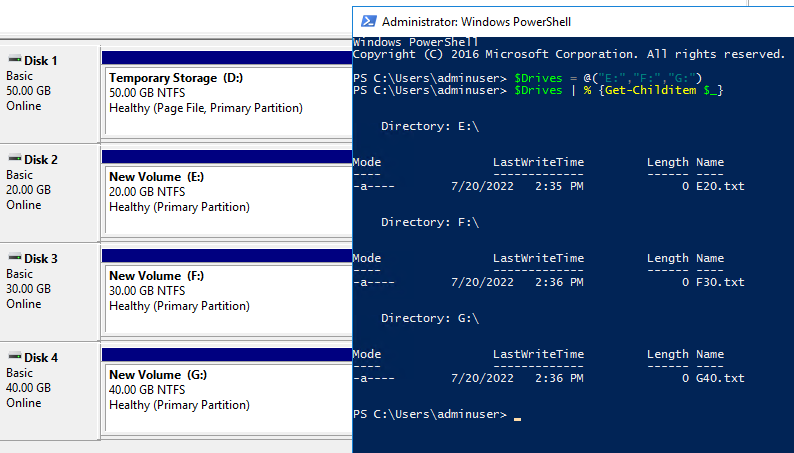
Then I did the same as before and removed the second item in the list and then checked to see what happened within the VM:
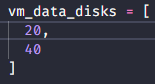
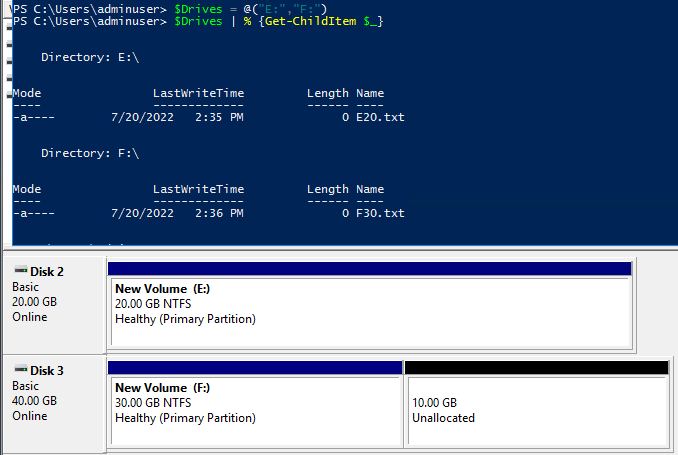
This did not turn out how I originally hypothesized, though I’m not surprised by the outcome. As you can see, rather then removing the second drive it removed the third drive and then modified the second drive to match the configuration of what had been the third. The data and configuration on the second drive was retained, while the data on the third drive was removed.
If I had to guess, I assume that the index of the object created represents that object in the terraform state. So only the items with indexes equal to or greater then the object that was changed are actually modified. In this case, the “third” drive was actually removed. Because the second item in the list had a different drive size (what was the “third” disks drive size), it was modified.
When to use count or for_each #
I don’t have any firm rules, and I wasn’t really planning on using this test to establish any. However, based on this test, I think we can make some general suggestions.
It may be better to use count in the following instances:
- You are creating a number of resources where any configuration changes to the object after creation are trivial (don’t need to persist).
- You are creating a number of identical resources that won’t be modified after creation.
The circumstances to use for_each are basically the reverse:
- You are creating a number of objects that might be modified, and each objects configuration needs to be retained in the event the input variable for your for_each is modified
This seems to align well with the statement Terraform makes in their documentation.
Closing #
If you found this interesting, feel free to check out some of my other Terraform posts, like how to use these methods as inputs to dynamically create different types of resources with a single module.
As always, feel free to reach out to me on Twitter @ZabinskiTech if you have questions or think I missed anything.